3
nézetek

Renat nem az első alkalommal, amikor egy vendég szerző beszél Layfhakere. Korábban megjelent egy kiváló anyag tőle, hogyan lehet létrehozni egy képzési terv: fő könyv és online források, valamint inkrementális algoritmus hozzon létre egy képzési tervet.
Ebben a cikkben néhány egyszerű technikát, amely segítséget egyszerűsíti a munkát az Excel. különösen hasznosak, akik részt vesznek a vezetői jelentések, előkészíti a különböző elemzési jelentések alapján kirakodott 1C jelentések és egyéb ilyen előadások és diagramok vezetés. Ne úgy, mintha abszolút újdonság - az egyik vagy másik formájában, ezek a módszerek természetesen tárgyalt fórumok vagy cikkben említett.
VLOOKUP (VLOOKUP) És PGR (HLOOKUP) csak akkor működik, ha a cél értékek az első oszlopban vagy sorban a táblázat, ahonnan szeretne adatokat.
Más esetekben, két lehetőség van:
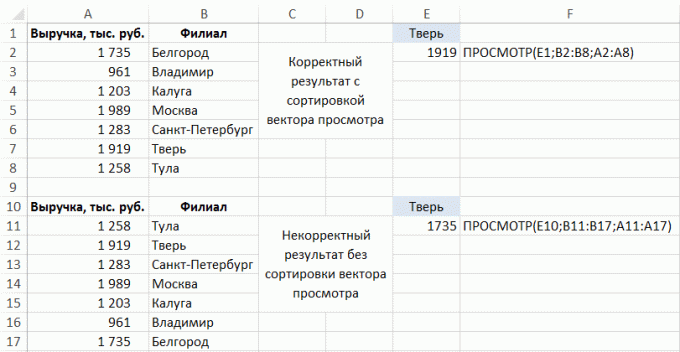
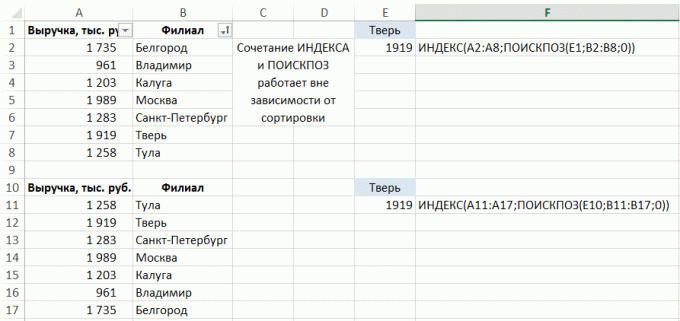 Syntax lehetőségek:
Syntax lehetőségek:Az feladat -, hogy töltse ki a sejtek az értékeket az oszlopban a fenti (feltéve, hogy állva minden sorban a táblázat, nem csak az első blokk sorban könyvek a témában):
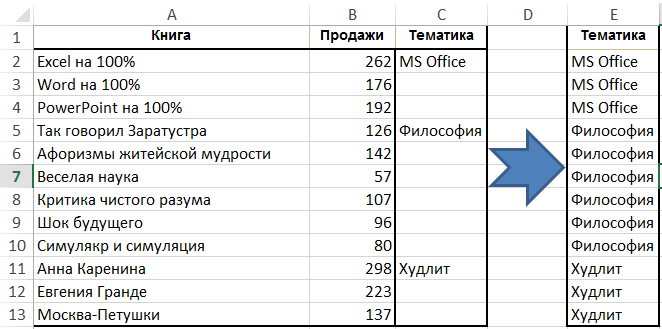
Jelölje ki az oszlopot „Tárgy” nyomja meg a szalagot a csoport a „Home” gomb „Keresés és válassza ki a» → «Jelölje ki a sejtcsoport» → «Blank sejt „, és kezdjük el beírni a formula (azaz véget egyenlőségjel), és utal a sejt felülről, egyszerűen nyomja meg a felfelé mutató nyilat billentyűzetet. Ezután nyomja meg a Ctrl + Enter. Ezt követően, az adatok menthetők érték, mert a képletek már nincs szükség:

Ahhoz, hogy megértsük a komplex képletű (amelyben például függvényargumentum alkalmazott egyéb függvény, azaz bizonyos funkciók be vannak ágyazva a többi), vagy találni benne hiba forrása, gyakran kell számítani része. Két egyszerű módja van:

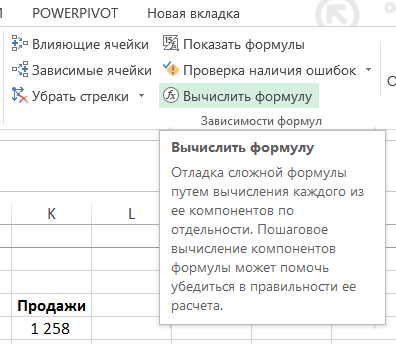

Annak meghatározására, hogy mely sejtek függ a képletet a csoport „formula” a szalag, kattintson a gombra „Trace Előzmények”:
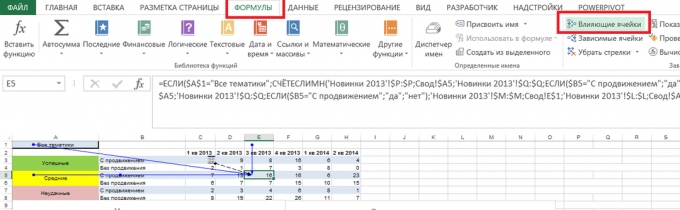
Vannak nyíl, ahonnan az eredmény attól függ.
Ha a szimbólum jelenik meg a kiválasztott képen pirossal, a képlet függ sejtek, amelyek a más listák vagy egyéb könyvek:

Rákattintasz, azt látjuk, hogy hol a befolyása a cella vagy tartomány:
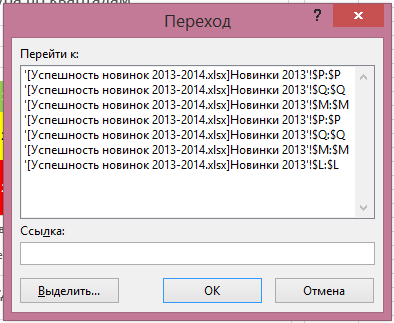
Továbbá a „Trace Előzmények” Van egy gomb „eltartottak” dolgozó ugyanúgy: megjeleníti nyilak az aktív cella a képletet sejtek múlik rajta.
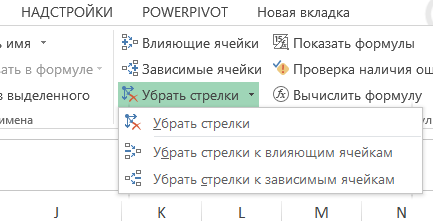
Gomb „Remove nyilak” található ugyanabban a blokkban, lehetővé teszi, hogy távolítsa el Előzmények, az eltartottak, vagy mindkét fajta egyszerre nyilak:
Tegyük fel, hogy több hasonló lapot az adatokat, hogy a felvenni kívánt, meg vagy feldolgozott más módon:
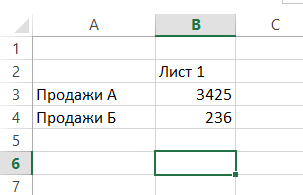

Ehhez a cellában, amelyben szeretné látni az eredményt, adja meg a standard formula, mint a SUM (SUM), és írja be az érv kettőspont követi, és az utolsó név az első lapot a laplista van szüksége folyamat:
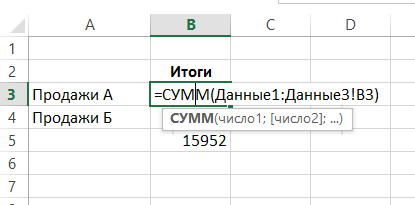
Lesz kap az összeg ceiiacímet B3 lap „Data1”, „Data2”, „DATA3”:
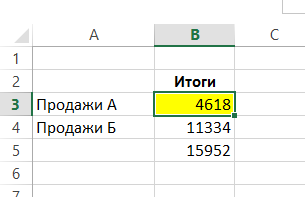
Az ilyen címzési munkák lapok elrendezve egymás után. A szintaxis: FEATURE = (pervyy_list: posledniy_list hivatkozás a tartományban!).
Az alapelvek a dolgozó szöveget Excel és néhány egyszerű funkciók állíthatók elő kifejezéseik jelentések. Több elvei munka a szöveggel:
Példa létrehozása sablon kifejezések használatával képletek:

Eredmény:

Ebben az esetben a függvény mellett JEL (CHAR) (hogy megjelenjen az idézetek) függvény használatával IF (IF), amely lehetővé teszi, hogy módosítsa a szöveget Attól függően, hogy van egy pozitív trend az értékesítés és a funkció a szöveges (text), amely lehetővé teszi, hogy megjelenjen a szám bármilyen formátumban. A szintaxis az alábbiakban ismertetjük:
TEXT (érték; formátum)
A formátumot idézőjelben ugyanúgy, mint ha megadott egy egyéni formátumot a „Format Cells”.
Automatizálhatod bonyolultabb szövegeket. A praxisomban volt, hogy automatizálják hosszú, de a rutin észrevételeket a számlákon „formátumú szám csökkent / rózsa A XX a terv elsősorban a növekedés / csökkenés az FAKTORA1 XX növekedése / csökkenése az FAKTORA2 YY... »a változó lista tényezők. Ha írsz ilyen megjegyzéseket gyakran, és a folyamat az írás is algorithmization - érdemes egyszer zavarba hozzon létre egy képlet vagy makró, amely takarít meg legalább a munka egy részét.
Amikor kombináljuk a sejtek visszatartott csak egy érték. Excel figyelmeztet, ha megpróbálja egyesíteni sejtek:
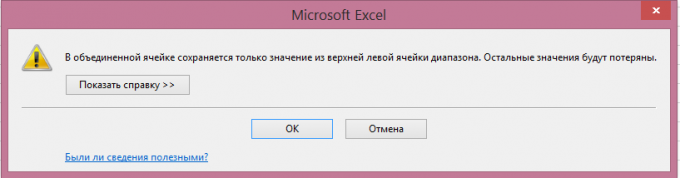
Ennek megfelelően, ha volt egy képletet, amely attól függ, hogy minden cella, így megszűnik a munka után unió (bug # N / A sorok 3-4 példa):
Egyesíteni sejtek, megőrizve az adatok mindegyik (talán van egy képlet, mint ebben a példában, az absztrakt; érdemes cellákat egyesíteni, de minden adatot a jövőben, vagy elrejteni a szándék), össze bármelyik cella lemez, jelölje ki őket, majd használd a „Format Painter” átadása méret a sejteken van szüksége, és kombinálni:

Ha meg kell építeni egy összevont több adatforrás, szükséges hozzá, hogy a szalag vagy gyorselérésieszköztár „Kimutatás varázsló és táblázatok”, ahol van ilyen lehetőség.
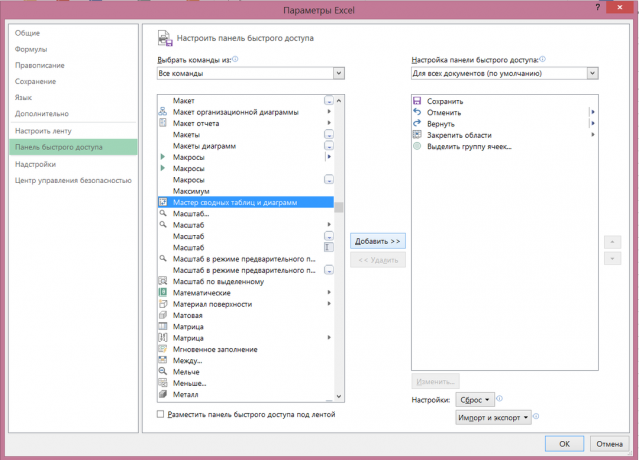
Ezt megteheti a következő: „File» → «Beállítások» → «gyorselérésieszköztár» → «Minden csapatban» → «Kimutatás varázsló és diagramok» → «Add»:
Ezt követően, a szalag lesz a megfelelő ikonra, kattintással ami kiegészítve a mester:

Ha rákattintunk, akkor egy párbeszédablak:
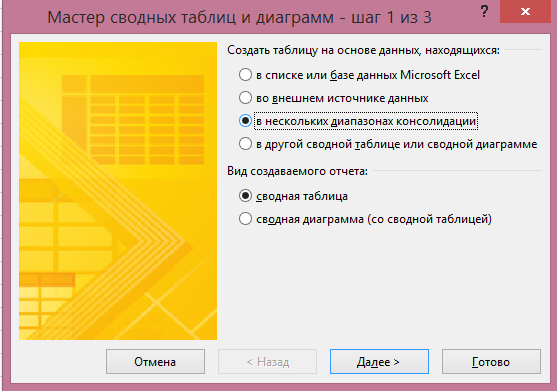
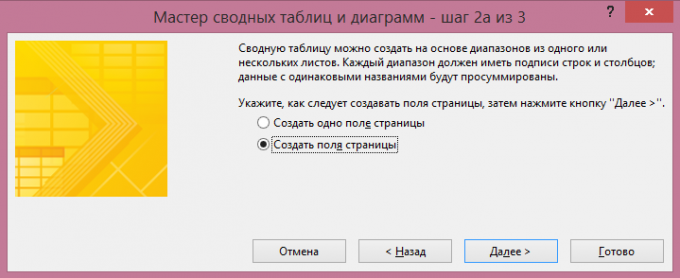
Ebben meg kell választania „Néhány zenekar konszolidáció” és kattintson a „Tovább” gombra. A következő részben, akkor válassza ki a „Create egy oldalon területen” vagy „Oldal létrehozása terén.” Ha azt szeretnénk, hogy magad felér egy nevet az egyes adatforrások - válassza ki a második tétel:
A következő mezőbe, add mind a tartományok alapján, amelyre építeni egy összefoglaló, és kérje meg őket a neveket:

Azt követően, hogy, ad otthont a kimutatás az utolsó párbeszédablak - egy meglévő vagy egy új munkalapot:
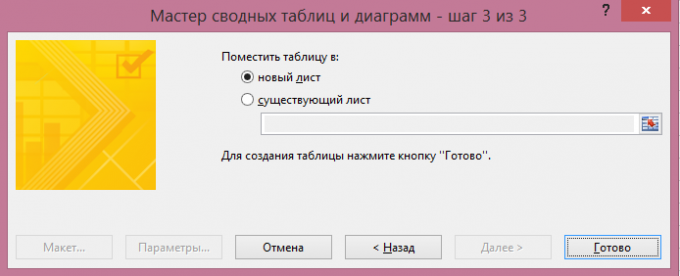
Report Kimutatás készen áll. A szűrő „Page 1” lehet választani csak az egyik adatforrások ha szükséges:
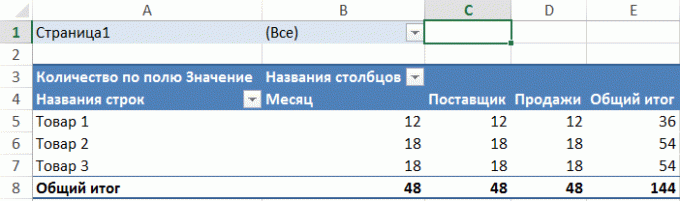
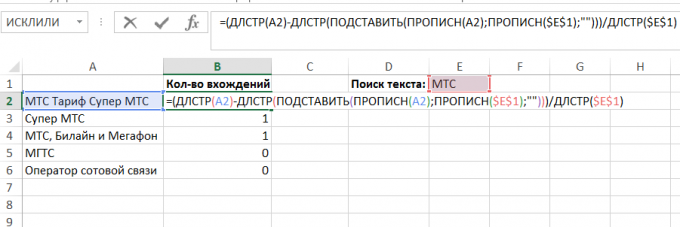
Ebben a példában oszlopában van néhány sornyi szöveget, és a mi feladatunk -, hogy megtudja, hogy hányszor mindegyik megfelel a kívánt szöveget az E1-es cellában:
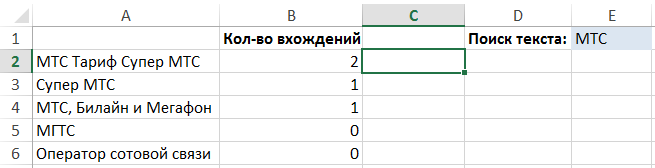
Hogy oldja meg ezt a problémát, akkor egy összetett képlet, amely a következő funkciókat:
Találni egy bizonyos bejegyzést egy szöveget a másikra, akkor el kell távolítani annak összes előfordulását az eredeti, és hasonlítsa össze a string hossza az eredeti:
LEN ( "Tarifa Super MTS MTS") - LEN ( "Super Rate") = 6
És akkor elosztjuk a különbséget a vonal hosszát, kerestünk:
6 / LEN ( "MTS") = 2
Ez kétszerese a vonal „MTS” az eredeti.
Meg kell még nyelvén írt algoritmus képletek (jele „text” a szöveget, amit keres belépési és „kívánatos” - az előfordulások számát, hogy mi érdekel):
= (LEN (szöveg) -DLSTR (SUBSTITUTE (FELSŐ (szöveg); FELSŐ (keresett a); ""))) / LEN (keresett a)
A mi példánkban, a képlet a következő:
= (LEN (A2) -DLSTR (SUBSTITUTE (FELSŐ (A2); FELSŐ ($ E $ 1); ""))) / LEN ($ E $ 1)